
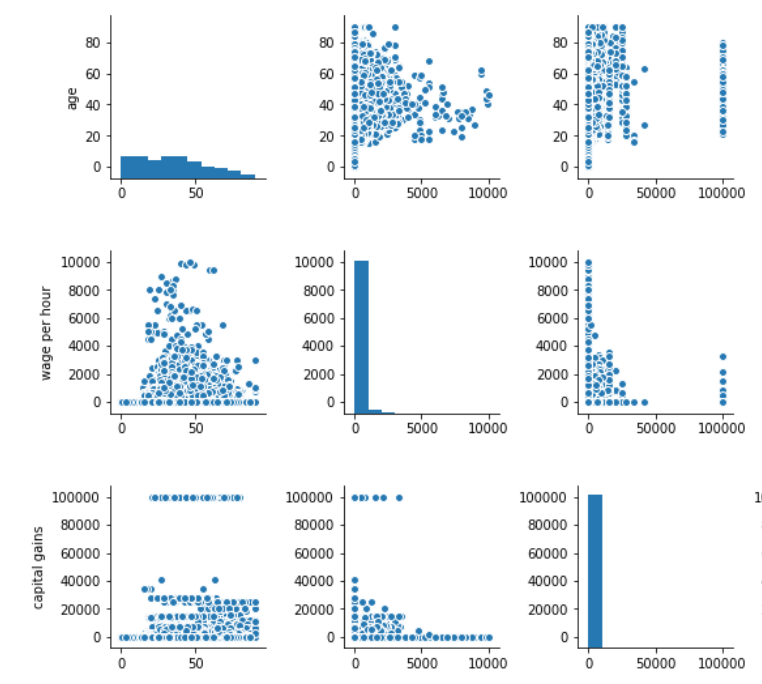
Kitquant Service - Predictive Analysis
At Kitquant, we frequently use Predictive Analysis to solve a variety of business problems, e.g. Credit Scoring, Sales Forecasting. I put on my github is a basic example that illustrates a Data Science approach the problem, including linear and non-linear modelling. Please contact us if you need more information regarding our technology!

Deep Learning with Python
Francois Chollet is one of the world's Deep Learning leader and this book is a gem for those who need an easy-to-understand approach but also concrete examples to use for business applications. Francois wrote the powerful Keras library, which provides ready to use Deep Network, like CNNs, RNNs, LSTMs. At Kitquant we find that Deep Learning is unavoidable when it comes to computer-vision or Natural Langage Processing problems. More specifically, and used in combination with traditional NLP libraries like NLTK, we frequently rely on these powerful tools to perform text classification and sentiment analysis. Let us know if you need more information about our services

An Executive’s Guide to Machine Learning
This McKinsey Quarterly article underlines the key strategies that executives could use in regards to machine learning. Machine Learning is the use of algorithms that can “learn” without using rules-based programming. Machine Learning is currently tremendously needed in the business world, due the huge amount of data in circulation, much of it yet to be analyzed. Traditional industries and companies, such as GE and the US National Basketball Association have all started using machine learning for better predictions. The article also gives tips to companies who want to use machine learning for M&A, as well as to top management on how to encourage behavior change in employees to employ analytics.
What to Expect for Big Data and Apache Spark in 2017
In this Spark Summit talk, What to Expect for Big Data and Apache Spark in 2017, Matei Zaharia discusses the newest trends in Spark and how businesses are utilizing its framework. Spark is quickly becoming one of the hottest tools in data science, and Zaharia discusses the hardware, users, and applications that are make it so useful. The highlights of the talk include a mention of Spark's Project Tungsten, Spark’s growth over the past 2 years, and the importance of real-time data analysis in our current business environment.

Wall Street and The New Gold Rush?
In this valuable read, Matt Turck analyzes Wall Street’s recent interest in what is known as “alternative data.” This is raw data collected by startups, which can be used for market prediction purposes. In 2016, Foursquare was able to predict a 30% drop in Chipotle Q1 sales before the company itself. It is this kind of data that hedge funds think will allow them to outperform the market. However, Turck also details the difficulties of Startups and Wall Street cooperation, and point out some new marketplace solutions which can close the difficulties gap.
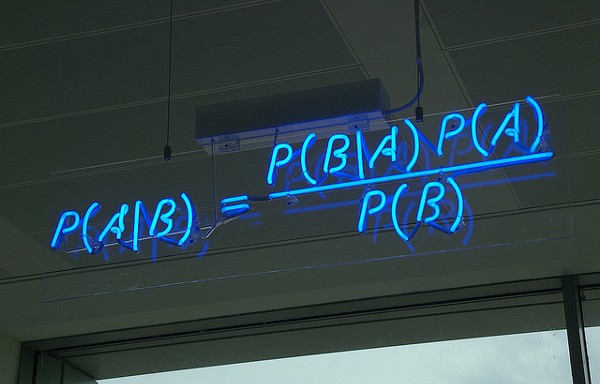
Bayesian Basics, Explained
In this article published on kdnuggets, Professor Andrew Gelman of Columbia University and marketing scientist Kevin Gray cover the basics of Bayesian statistics. Bayesian stats are useful for mixing several sources together. They are also more precise than simpler methods such as weighting. They do, however, require strong hypothesis on prior distributions, and a complex fitting process in the case of multivariate problems.
Yann LeCun - Deep Learning and the Future of AI
One of the latest versions of Yann's presentation about Deep Learning, in which he retraces the progress made in Computer Vision and Speech Recognition over the past 30 years. See how ConvNets began to identify multiple objects in video motions and won all the competitions. Yann, who was one of several scientists pioneering the field back in the early 80s, is now the boss of Facebook Data Science research team. He also gives super interesting insights into Metric Learning (used by Facebook for face recognition), and the latest trend of Adversarial Training.

Ensemble Learning
Besides focusing on methods such as bagging and boosting, this book also offers a generalized model of Ensemble Methods. The concept is to perform regularization by fitting a base learner (e.g. a single decision tree) on various parameter changes and input subsets, and then combine the individual results by averaging or voting. This gives a tremendous boost to performance (i.e. reduces the error rate). The book, which is not too technical, provides a great introduction to some important Data Science concepts.
Recommender Systems
Recommender systems seek to predict the "rating" or "preference" that a user would give to an item. They have become extremely common in recent years, and are utilized in a variety of areas - popular applications include movies, music, news, books, research articles, search queries, social tags, and products in general. Kitquant will deliver a recommendation engine and integrate it into your app or website in a very short time. This is one of our best-sellers, contact us now for further details.
Predictive Analysis
As the name suggests, Predictive Analysis aims to predict a future outcome by analyzing current data. Typically used in areas like online advertising and sales volume forecasting, Predictive Analysis employs methods such as Multivariate Linear Regression, Bayesian Inference and Random Forests. Apart from implementing standard tools, Kitquant provides customization that allows for the exclusion or grouping of certain data. Following a rigorous data science protocol, we also provide an estimate of the predictive power.
Machine Learning
Kitquant extensively uses Machine Leaning algorithms, either supervised (e.g. Multivariate Regression, Decision Trees, Genetic Algorithms) or unsupervised (Clustering). We rely on public libraries to implement the algos. Contact us for more info.
This video gives good insights into Criteo's technology for optimizing ad metrics like cost-per-click and cost-per-order. Interestingly, they often use logistic regression instead of more complex tools in order to meet real-time performance needs.
Python
Python is a widely used high-level, general-purpose, interpreted, dynamic programming language with a design philosophy that emphasizes code readability. Its syntax allows programmers to express concepts in fewer lines of code than in other computer languages such as C++ or Java, which makes the language particularly suitable for Data Science programming. Kitquant has expertise in a broad range of Python third-party libraries :- Numpy- Pandas- Scipy- Scikit-learn- Cython (C-embedded tool for acceleration)- Deap (genetic algos)- Kivy (real-time vizualisation).
Big Data
If you need more power to process large quantities of data, Kitquant can help you by deploying multiple Amazon EC2 instances. We can also optimize performance through multiprocessing and embedded C.

Quantitative Finance
Kitquant can work with you to develop your risk or quantitative research system. Contact us for further information.

The Elements of Statistical Learning
This is the standard reference book in the field : T. Hastie, R. Tibshirani and J. Friedman provide details of various Data Science methods and mathematical tools. The title itself shows how Machine Learning is rooted in statistics. This book is available online here, a must read!
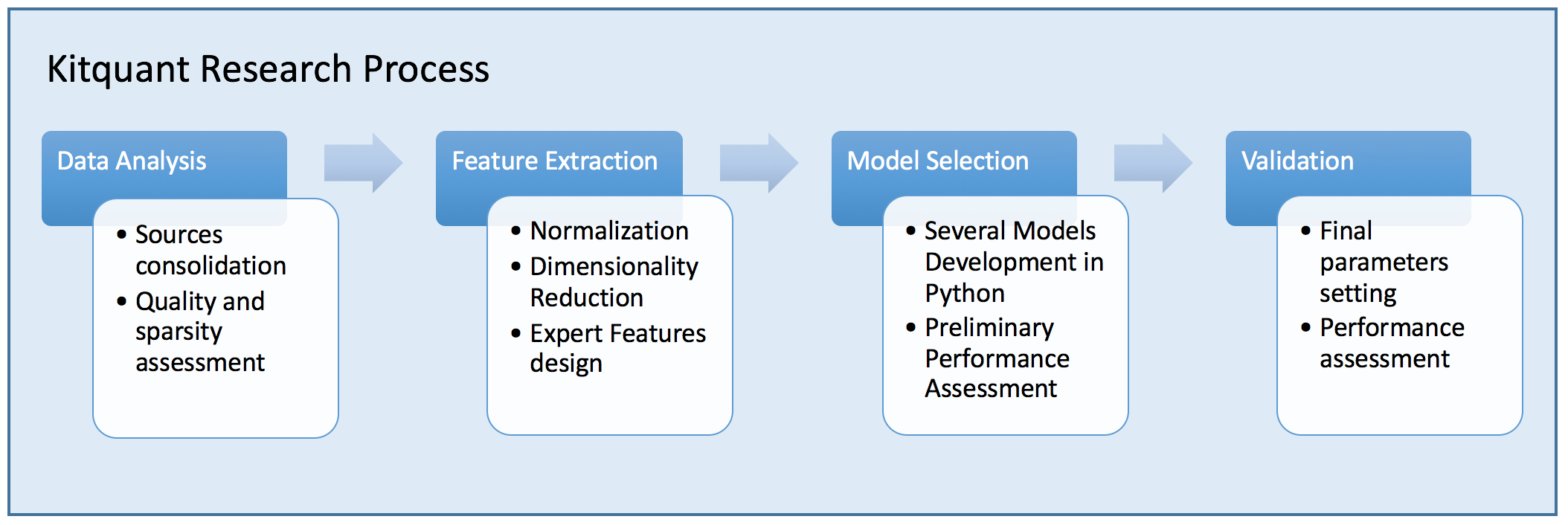
Research
Research is the first stage of our work. When we start working with you, we begin by analyzing your current dataset : identifying features and estimating data quality. Next, we select a model by comparing the results of various algorithms. Finally we set the final parameters (such as complexity) through a final cross-validation. Kitquant follows a rigorous Data Science approach by separating the training data from the validation data both for selecting the model and for calibrating the parameters. As a result, we can produce a relevant performance estimate that we share with you at the end of the research phase - for predictive analysis, for instance, you'll know what to expect.
Development
At this stage, the objective is to develop a fully operational component. Key questions are: what is the process frequency (real-time, overnight, on demand) ? What is the output format ? Kitquant works members of your IT team as they make the technological choices and integrate the component into your systems. We follow best practices for coding (review, versionning), testing (unit testing, integration) and release (parallel run, approvals).
Organization
Our Management Consulting experience enables us to help you put in place an organization that will add maximum value to the technological process. This aspect is frequently neglected. Establishing a Data Quality process or generating feedback for business management is as important as developing best-in-class systems.
Support
Once the component is up and running, you can enroll on one of our support plans. Please contact us to find out more about our plans and rates.